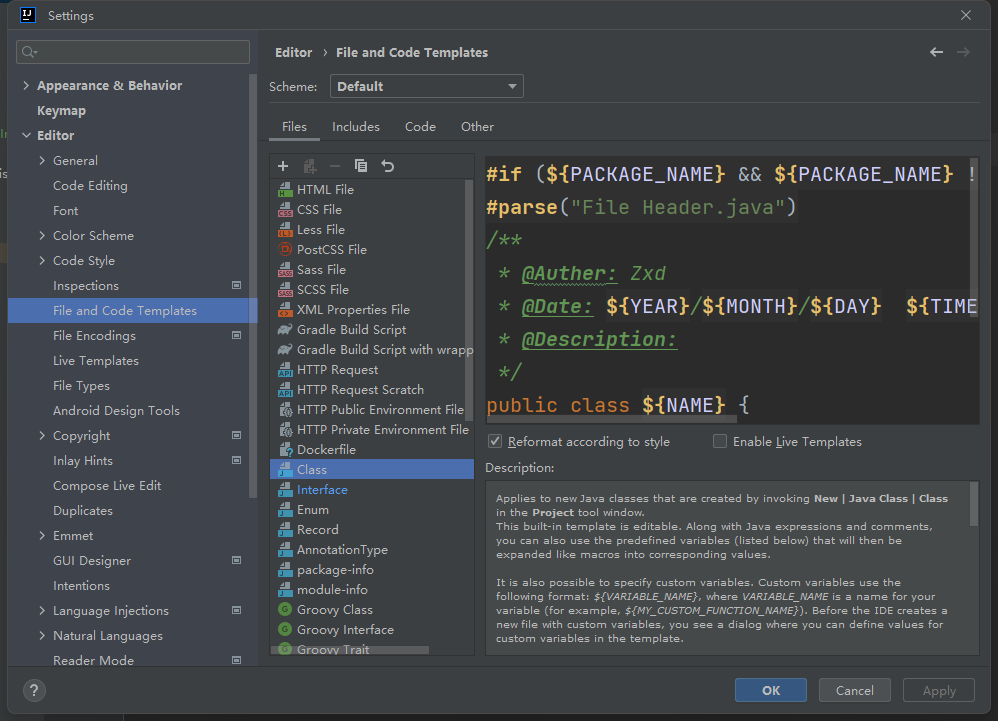
【C语言简介】
计算机的运行由CPU指令控制,为了让计算机执行指定功能,需要将这些功能对应的指令数据集中存储在一起,制作为一个计算机文件,这个文件称为程序,CPU通过读取程序中的指令确定要执行的功能,制作程序时无需直接编写指令数据和数学数据,这些数据使用代码表示,从而方便记忆和编写,之后使用编译器和汇编器将代码转换为对应的指令数据和数学数据。
程序代码分为两种类型:汇编语言代码、高级语言代码。
1.汇编语言,每条CPU指令都有对应的代码,可以将指令随意组合使用,优点是灵活,缺点是繁琐。
2.高级语言,将单个指令或多个指令实现的常用功能使用一条简化代码表示,代码编写更简单,缺点是不够灵活,因为不直接使用指令,所以无需学习枯燥的CPU运行方式和CPU指令集,高级语言代码由编译器转换为对应的汇编代码,之后再由汇编器将汇编代码转换为指令数据。
C语言是编程领域的基本功,它定义了编程所需的基础行为,几乎所有程序都是由这些基础行为组成,主要语句如下:
1.创建数据,简化数据的创建方式,数据的存储由编译器自动管理,无需手动管理。
2.数据名,使用一个自定义名称调用数据,比在汇编中使用内存地址、寄存器调用数据更方便记忆。
3.指针,使用间接内存寻址调用数据,解决某些情况下使用数据名调用数据不灵活的问题。
4.运算符,将各种数学运算指令、逻辑运算指令使用运算符代替,方便使用。
5.数组,存储一组同型数据。
6.结构体,存储一组异型数据。
7.共用体,实现存储空间重用,解决内存容量不足的问题。
8.有条件执行语句,根据逻辑判断结果确定是否执行一组指令。
9.循环语句,循环执行一组指令。
10.跳转语句,跳转到指定代码处执行。
11.函数,将代码模块化,一种功能对应一个函数,方便调用这组代码实现的功能,同时也方便代码的查看和修改。
如果以上语句依然无法满足你的需求,C语言还支持在高级语言代码中内嵌汇编代码,可以根据自己的需求随意设置任意指令。
C语言代码基础规则
1.C语言代码由多个语句组成,每个语句提供一个独立的最小功能,C语言语句使用;符号结尾,多条语句可以使用同一行存储,也可以分别占用一行,编译器在编译代码时会忽略多行语句中间的空格与换行。
2.数据名不能使用C语言关键词、不能以数字开头、可以使用_符号,GCC编译器10版本之前使用ASCII编码存储数据名,数据名只能使用英文,GCC10版本之后的数据名使用UTF8编码存储,可以使用中文作为数据名。
3.C语言使用 // 定义单行注释内容,使用 /* */ 定义多行注释,注释不会被编译,只用于说明一段代码的功能和作用。
int a = 5; //创建一个数据,数据类型为int,表示4字节有符号整数,起名为a,赋值为5,语句以;符号结尾程序输入输出数据的方式
程序有数据输入输出的需求,用户通过向程序输入数据控制程序的运行,程序执行完某个功能后向用户输出执行结果。
程序根据输入输出数据的方式可以分为两类:控制台程序,图形界面程序。
控制台程序
控制台程序使用终端进行数据的输入和输出,输入输出方式如下:
1.输出数据,输出数据以字符为主,直接将字符显示在屏幕中。
2.输入数据,主要使用键盘,用户按下键盘中的按键向CPU发出数据,之后由程序读取这些数据。
图形界面程序
因为控制台程序使用不方便,所以就有了图形界面程序,图形界面程序会在显示器中显示一个图形,称为程序界面(英文简称GUI),程序界面内部可以嵌套显示其他小型图形,称为控件,控件还可以继续嵌套子控件,每个控件都可以单独进行数据的输入输出,一个控件与程序提供的一种功能进行绑定,这种将程序模拟为一个图形的方式更方便用户使用。
图形界面程序数据输入输出方式如下:
1.输出数据,数据输出到程序界面内,输出数据可以是字符、图形、动画,通过图形的方式输出执行结果更直观易懂。
2.输入数据,使用键盘、鼠标两种设备输入数据,通过鼠标移动界面内的指针确定要输入数据的控件,使用更方便。
两种类型的程序是互补关系,而非代替关系,图形界面程序使用方便,但是会占用更多的内存,适用于以易用性为主的用户程序,控制台程序输入输出数据的方式更简单稳定,适用于服务器程序、功能简单的单片机程序。
之后讲解C语言编程时使用控制台程序、linux操作系统、gcc编译器。
【数据类型】
计算机数据分为整数和浮点数,其中整数又分为有符号数和无符号数,并且有多种长度,C语言为所有的数据类型定义了统一的表示代码。
整数型
unsigned char,无符号1字节整数,表示范围0-255。
unsigned short,无符号2字节整数,表示范围0-65535。
unsigned int,无符号4字节整数,表示范围0-4294967295。
unsigned long long,无符号8字节整数,表示范围0-18446744073709551615。
signed char,有符号1字节整数,表示范围 -127 - 128。
signed short,有符号2字节整数,表示范围 -32768 - 32767。
signed int,有符号4字节整数,表示范围 -2147483648 - 2147483647。
signed long long,有符号8字节整数,表示范围 -9223372036854775808 - 9223372036854775807。
unsigned、signed为符号关键词,用于设置数据是否有符号位,若省略符号关键词则默认为有符号数。
char、short、int、long为长度关键词,定义数据时不能省略长度关键词。
其中long长度类型很特殊,在早期long与int都可以表示4字节长度,所以8字节长度就被定义为两个long。
浮点型
float,单精度浮点型,长度4字节。
double,双精度浮点型,长度8字节。
long double,长双精度浮点型,在VC++中长度8字节,在GCC中长度16字节。
布尔型
布尔型数据是单字节整数,使用_Bool关键词表示,本质上与unsigned char类型相同,只不过布尔数据用于存储逻辑运算的两种结果,只能赋值为0和1,1表示true(对、正确、符合),0表示false(错误、不符合),若赋值为大于1的数据,则编译器当做1处理。
字符型
文字在计算机中需要使用数据表示,每个文字绑定一个数据,称为此文字的编码,一套字符编码称为一种字符集。
用于存储字符编码的单字节整数称为字符型数据,本质上与char类型相同,所以字符型数据直接使用char关键词表示,char类型数据也可以使用文字进行赋值,编译器会自动转换为对应的字符编码。
英文字母数量很少,使用一个字节即可完全表示,通用的英文字符集是ASCII字符集,中文有上万个文字,需要使用2-3个字节表示,常用的可以存储中文的字符集有GB18030、UTF8。
ASCII字符集常用字符编码如下:
------------
控制字符0 空字符
32 空格9 水平空白
11 垂直空白8 退格
127 删除10 换行
13 回车------------
符号33 !
34 "
35 #
36 $
37 %
38 &
39 '
40 (
41 )
42 *
43 +
44 ,
45 -
46 .
47 /------------
数字48 0
49 1
50 2
51 3
52 4
53 5
54 6
55 7
56 8
57 9------------
符号58 :
59 ;
60 <
61 =
62 >
63 ?
64 @91 [
92 \
93 ]
94 ^
95 _
96 `123 {
124 |
125 }
126 ~------------
大写字母65 A
66 B
67 C
68 D
69 E
70 F
71 G
72 H
73 I
74 J
75 K
76 L
77 M
78 N
79 O
80 P
81 Q
82 R
83 S
84 T
85 U
86 V
87 W
88 X
89 Y
90 Z------------
小写字母97 a
98 b
99 c
100 d
101 e
102 f
103 g
104 h
105 i
106 j
107 k
108 l
109 m
110 n
111 o
112 p
113 q
114 r
115 s
116 t
117 u
118 v
119 w
120 x
121 y
122 z
数据的创建和使用
在C语言中创建一个数据也称为定义数据,定义数据时首先指定数据类型,之后设置数据名称,数据定义后使用 = 符号赋值,可以在定义时赋值,也可以在定义之后赋值。
#include <stdio.h>
int main()
{
int a = 9; //有符号整数,数据名为a,使用=符号赋值为9
a = 10; //使用数据名调用数据,这里调用数据修改它的值
a = 0xc; //可以使用16进制方式赋值
float b = 3.14; //浮点型
char c = 'a'; //字符型,使用字符赋值时,字符放在''符号内
_Bool d = 1; //布尔型
int i1=1, i2=2, i3=3; //使用一条语句定义多个同类型数据,此时只需要指定一次类型 return 0;
}
使用typedef关键词可以为数据类型增加一个新的名称,可以设置为任意自己喜欢的名称,但是不能与其它C语言关键词冲突。
#include <stdio.h>
typedef char int8;
typedef short int16;
typedef int int32;
typedef long long int64;
int main()
{
int8 a; //1字节有符号整数
int16 b; //2字节有符号整数
int32 c; //4字节有符号整数
int64 d; //8字节有符号整数
int x; //原有类型名依然可用,不会失效
return 0;
}数据赋值时的类型转换
使用=符号对数据进行赋值时,若=符号两边的数据类型不同,则编译器会自动进行类型转换,转换规则如下:
1.右值长度小于左值,右值会自动扩充长度,不会产生错误。
2.右值长度大于左值,接收数据的左值将会发生溢出,C语言编译器不会进行赋值溢出检查,程序执行时可能会产生错误。
3.浮点数赋值给整数,编译器使用sse指令将浮点数转换为整数,使用截断转换法,丢弃小数位。
4.整数赋值给浮点数,编译器使用sse指令将整数转换为浮点数,整数值太大会丢失精度。
#include <stdio.h>
int main()
{
unsigned short a = 257; //257转换为二进制 = 1 0000 0001
unsigned char b = a; //高位被丢弃,b为1
printf("%hd\n", a); //printf为终端输出函数,输出b的值,这里输出1
float c = 3.14;
int d = c; //d=3,丢弃小数位
printf("%d\n", d); //输出3
return 0;
}变量与常量
定义的数据根据是否可以修改分为变量和常量,变量定义后可以修改,常量定义后不能修改。
定义数据默认为变量,额外添加const关键词则为常量,常量必须在定义时赋值(作为参数时除外,参数由调用者赋值),赋值之后不能修改,若定义常量时没有赋值,则会使用其占用内存原有的值,这种使用方式是错误的。
const int a = 9;寄存器变量
使用register关键词定义寄存器变量,编译器会尽量将变量存储在寄存器中,从而增加数据的读写速度,但这并非是强制性的。
register int a = 9;不稳定变量
使用volatile关键词定义不稳定变量,用于告知编译器这个变量的值会在编译器不可预知的情况下发生改变,让编译器尽量不要进行代码优化,防止产生错误。
volatile int a = 1;临时数据
临时数据是直接使用的、没有指定类型和名称的数据,临时数据默认为常量,用完即废弃,多数情况下使用立即数寻址、寄存器寻址,临时数据若需长期保存需要定义一个有名称数据并使用=符号接收它的值。
int a = 5;
int b = a + 1; //1为临时常量
临时数据的类型由编译器自动确定,若编译器无法确定也可以使用代码人为控制类型,当代码控制的类型与编译器冲突时以编译器为准。
(char)9; //整数使用 (类型名) 控制类型,这里设置为char类型
3.14f; //浮点数后缀f,设置为float类型
3.14d; //浮点数后缀d,设置为double类型
3.14l; //浮点数后缀l,设置为long double类型
若编译器无法确定临时数据的类型,也没有使用代码人为设置临时数据的类型,则数据默认使用如下类型:
1.整数,默认为int类型。
2.浮点数,默认为double类型。
【运算符】
数学运算
+,加法
-,减法
*,乘法
/,除法,除数不能为0
%,取余,只计算除法的余数
++,自加1
--,自减1
运算符优先级
复合运算式中运算符的优先级与数学相同,首先计算乘除,之后计算加减,可以使用小括号控制运算符的优先级。
++ 和 -- 用于对一个变量进行加1和减1操作,可以用于复合运算式中,有如下两种使用形式:
1.设置在变量名之前,变量首先进行自加1或自减1运算,之后参加其它运算。
2.设置在变量名之后,变量首先参加其它运算,之后进行自加1或自减1运算。
注:为了防止混乱,一般使用a++这种方式。
运算结果的调用
运算式本身即表示运算式结果,可以将运算结果赋值给另一个变量进行保存,也可以直接使用。
#include <stdio.h>
int main()
{
int a=5, b=9;
int c = a+b; //定义变量c保存a+b运算结果
printf("%d\n", c); //输出运算结果
printf("%d\n", a+b); //直接使用运算式调用计算结果
return 0;
}乘法结果溢出
C语言的乘法结果并不会限制只能使用比乘数长度更大的数据存储,这一点与乘法指令不同,所以C语言的乘法结果可能会出现存储溢出,编写代码时应该注意这种情况,必要时使用长度更大的数据接收乘法结果。
除法结果取整
C语言的整数除法运算不保留余数,若不能整除则对结果进行取整,取整方式有三种:
1.向下取整,取整后数据比原值小,正数去除小数位,负数去除小数位并减1,比如:3.5取整为3、-3.5取整为-4。
2.向上取整,取整后数据比原值大,正数去除小数位并加1,负数去除小数位,比如:3.5取整为4、-3.5取整为-3。
3.向零取整,取整后数据更接近0,正数负数都直接去除小数位,比如:3.5取整为3、-3.5取整为-3。
C语言使用向0取整规则,除法结果直接丢弃余数即可。
int a=7, b=2;
int c = a/b; //c为3参与运算数据的类型转换
参与四则运算的数据类型需要相同,若不同则编译器会自动进行类型转换,所有的基础数据类型都可以自动转换,转换后的数据可能会发生存储溢出,这一点与JAVA等语言不同。
1.不同长度的数据,长数据转短数据可能会发生溢出,高位数字被丢弃。
2.浮点数与整数,编译器使用sse指令转换浮点数与整数。
注:自动类型转换并不会影响数据原值,转换行为只发生在数学运算式内。
#include <stdio.h>
int main()
{
int a = 5;
char b = 10;
a = a * b; //b扩展为4字节,之后参与运算
printf("%d\n", a); //输出50 float c = 3.14;
a = a + c; //c转换为int类型
printf("%d\n", a); //输出53
return 0;
}
数学关系运算
数学关系运算用于判断两个数据的大于、小于、等于关系,运算结果为一个布尔值,关系正确返回1,错误返回0。
>,大于
<,小于
==,等于
!=,不等于
>=,大于或者等于
<=,小于或者等于
int a=0, b=1;
_Bool c = a==b; //c为0,表示不相等
浮点数比较
人类习惯使用十进制,在代码中定义数据时也是使用十进制,而计算机使用二进制,编译器会将代码中的十进制数据转换为二进制,转换整数时只要数据长度不溢出即可完全转换,而转换小数时很容易丢失精度,这将会导致错误,比如以下代码。
#include <stdio.h>
int main()
{
float a = 0.1;
float b = 0.2;
if((a+b) == 0.3) //判断a+b的结果是否为0.3
{
printf("等于\n");
}
else
{
printf("不等于\n"); //执行不等于
}
printf("%f\n", a+b); //输出a+b的结果,显示为0.3
return 0;
}上述代码之所以不相等,是因为二进制无法表示十进制的0.1、0.2、0.3,这三个数据在转换为二进制后都将丢失精度,导致最后a+b的结果不等于0.3,虽然使用printf函数输出时显示为0.3,但这是printf精简后的结果,计算机实际存储的值并非0.3。
逻辑关系运算
逻辑关系运算用于对逻辑运算结果继续进行逻辑运算,从而进行复杂逻辑判断,参与运算的是布尔型数据,运算结果还是布尔值,若参与运算的布尔数据大于1,当做1处理。
&&,与运算,判断两个布尔数据是否都为1,若都为1则运算结果为1,否则运算结果为0。
||,或运算,判断两个布尔数据是否至少有一个为1,若有一个为1或两个都为1则运算结果为1,若两个布尔数据全为0则运算结果为0。
!,非运算,将一个布尔数据取反值,1变为0,0变为1。
#include <stdio.h>
int main()
{
int a=1, b=2, c=3, d=4;
_Bool l1 = a < b;
_Bool l2 = c < d;
_Bool l3 = l1 && l2;
if(l3)
{
printf("逻辑关系成立\n");
}
else
{
printf("逻辑关系不成立\n");
}
return 0;
}
移位运算
移位运算对二进制数据的数字位进行移动操作,有如下两种移位运算符:
<<,左移,数据向高位移动,有符号数的数据位(符号位除外)左移溢出后会改变符号位的值,等同于汇编中的逻辑左移。
>>,右移,数据向低位移动,无符号数的所有位都参与移动,有符号数的符号位不参与移动。
右移运算与除法运算结果不一定相同,因为整数除法会进行取整,而右移只是直接丢弃低位。
比如计算 -14 除以 4,除法结果取整后为 -3,而使用右移2次的方式代替除以4时会得到 -4。
#include <stdio.h>
int main()
{
int a = -14;
int b = a / 4;
int c = a >> 2;
printf("%d\n%d\n", b, c); //输出 -3 和 -4
return 0;
}使用移位运算判断数据是单数还是双数。
#include <stdio.h>
int main()
{
unsigned int a = 9;
a = a<<31;
a = a>>31;
if(a)
{
printf("a为单数\n");
}
else
{
printf("a为双数\n");
}
return 0;
}
按位逻辑运算
按位逻辑运算对数据的所有二进制位进行逻辑运算,并根据运算结果组成一个新数据。
&,按位与运算,对两个数据所有同位置的数字进行与运算,若都为1则运算结果此位为1,否则此位为0。
|,按位或运算,对两个数据所有同位置的数字进行或运算,若有一个为1则运算结果此位为1。
^,按位异或运算,判断两个数据同位置的数字是否不同,若不同则运算结果此位为1。
~,按位取反运算,将一个数据的每个二进制位取反值得出运算结果。
#include <stdio.h>
int main()
{char a = 3; //二进制 = 0000 0011char b = 5; //二进制 = 0000 0101char c = a | b; //整合a与b二进制位中的1,c = 0000 0111printf("%d\n", c); //输出7c = c & 253; //253转二进制 = 1111 1101,使用按位与运算将变量c的第2位设置为0,c = 0000 0101printf("%d\n", c); //输出5c = c | 8; //8转二进制 = 0000 1000,使用按位或运算将变量c的第4位设置为1,c = 0000 1101printf("%d\n", c); //输出13return 0;
}转换字母大小写
ASCII字符集英文字母的编码有一个规律,同一个字母的大小写编码相差32,32的二进制为100000,大写字母的第6位为0,小写字母的第6位为1,可以通过修改第6位的方式来转换一个字母的大小写。
char a = 'a';
a = a & 0xdf; //0xdf转二进制 = 1101 1111,按位与,第6位设置为0,得出大写字母
a = a | 0x20; //0x20转二进制 = 0010 0000,按位或,第6位设置为1,得出小写字母实际项目中应该首先判断数据是否为英文字母,之后再进行转换。
判断单双数
使用按位或运算提取最低位的值,判断单双数。
#include <stdio.h>
int main()
{
int a = 9;
if(a & 1) //运算结果直接当做布尔值使用
{
printf("a为单数\n");
}
else
{
printf("a为双数\n");
}
return 0;
}转换大小端序
#include <stdio.h>
int main()
{
int a = 0x10203040;
int b = (a & 0xff) << 24 |
(a & 0xff00) << 8 |
(a & 0xff0000) >> 8 |
(a & 0xff000000) >> 24;
printf("0x%x\n", b); //输出0x40302010
return 0;
}编译器会转换为使用bswap指令。
赋值运算
赋值运算符可以只进行赋值,也可以将运算与赋值合并。
=,赋值
+=,加法运算并赋值
-=,减法运算并赋值
*=,乘法运算并赋值
/=,除法运算并赋值
%=,取余运算并赋值
<<=,左移运算并赋值
>>=,右移运算并赋值
&=,按位与运算并赋值
|=,按位或运算并赋值
^=,按位异或运算并赋值
int a = 5;
int b = 6;
b += a; //b=11
【查询数据长度与地址对齐值】
查询数据长度
使用sizeof关键词查询一个数据或数组的长度,单位为字节,sizeof会返回一个4字节或8字节无符号整数,表示查询到的长度。
#include <stdio.h>
int main()
{
int a = 9;
int b = sizeof(a); //查询a的长度
printf("a的长度为%d字节\n", b);
return 0;
}查询数据地址对齐值
使用_Alignof关键词查询在本计算机中一个数据或一个数据类型使用的地址对齐值,在C++中使用alignof关键词。
#include <stdio.h>
int main()
{
printf("char类型地址对齐值:%d\n"
"short类型地址对齐值:%d\n"
"int类型地址对齐值:%d\n"
"long long类型地址对齐值:%d\n",
_Alignof(char), _Alignof(short), _Alignof(int), _Alignof(long long));
return 0;
}设置数据地址对齐值
使用_Alignas关键词设置数据的内存地址对齐值。
#include <stdio.h>
int main()
{
int _Alignas(long long) a = 9; //设置变量a使用long long类型的地址对齐方式
int _Alignas(short) b = 9; //错误,只能向高设置,不能向低设置
return 0;
}
【数学运算优化】
编译器会对数据的定义、赋值、运算、使用进行优化,常见优化方式如下:
1.定义后不使用的数据会删除。
2.不会修改的变量会设置为常量,并尽量转换为立即数寻址。
3.多个相同的常量会合并为一个。
4.常量之间的运算会在编译期间直接计算出结果。
5.多余的数学运算会被删除。
其中最复杂的是程序执行期间的数学运算优化,编译器会使用执行速度更快的指令代替执行慢的指令,比如乘以2、乘以4会转换为使用左移指令代替,除法运算指令最为耗时,优化也最为复杂,当除数为常量、同时被除数不可预测时,若除数为2的乘方,则转换为右移,之后对右移结果进行向0取整规则调整,若除数不是2的乘方,则编译器转换为乘法,转换原理与减法转加法类似,也是先扩大再缩小,这里的缩小使用移位的方式实现。
使用10进制说明转换原理,75 / 5 = 15,可以转换为 75 * 2 = 150,150右移1次等于15,因为除以5与乘以2的结果相差10倍,所以除以5转换为乘以2之后只需要再除以10即可,而除以10可以无需计算,右移1次即可。
有符号变量除以9
int a;
scanf("%d",&a); //scanf为终端输入函数,输入a的值
int b = a / 9;编译器会将除法转换为如下指令:
mov edx,0x38e38e39 ;乘数写入edx
mov eax,ecx ;被除数写入eax
imul edx ;乘法
sar edx,1 ;取结果高位32位,等同于右移32位,再右移1位,共右移33位mov eax,ecx ;变量a写入eax,进行向0取整调整
sar eax,0x1f
sub edx,eax除法运算无法整除时结果需要向0取整,上述运算后,若被除数为负数,则计算结果需要额外加1才能满足向0取整的规则,末尾的两条指令用于实现被除数为负时的加1运算。
首先将eax中的被除数算数右移31位,之后乘法结果减eax,若被除数为负,则eax为-1的补码,减-1等同于加1,若被除数为正,则减0。
而在VC++编译器中会使用如下方式对除法结果进行向0取整调整,两种方式原理相同。
mov eax, 38E38E39h ;乘数写入eax
imul dword ptr [ebp-4] ;变量a乘以eax
sar edx, 1 ;乘法结果右移33位,得出除法结果mov ecx, edx ;运算结果写入ecx
shr ecx, 1Fh ;逻辑右移31位,目的是取符号位
add ecx, edx ;运算结果加ecx,若被除数为负则加1,若被除数为正则加0有符号变量除以7
int a;
scanf("%d",&a);
int b = a / 7;编译器会将除法转换为如下指令:
mov edx,0x92492493 ;乘数写入edx
mov eax,ecx ;被除数写入eax
imul edx ;乘法
lea esi,[rdx+rcx*1] ;乘法结果高32位 + 被除数,写入esi
sar esi,0x2 ;算数右移2位
sar ecx,0x1f ;向0取整调整
sub esi,ecx上面的优化方案中,被除数乘以一个数之后又执行了一个加法,之后右移2位得出除法结果,原因是编译器进行除以7的优化时,无法计算出误差较小、长度又不超过32位的乘数,所以编译器使用将被除数缩小再右移的方式进行优化。
右移2位等于除以4,这里将除以7转换为除以4,两者若要相等的话,被除数必须首先减去自身的3/7,这样才能保证其1/4等于原值的1/7。
而计算被除数的3/7却又产生了另一个除法,实际上这个除法也会被编译器优化为乘法,首先被除数乘以0x92492493,之后使用rdx,等于乘法结果右移32位,这个结果不算符号位的话,就是被除数的3/7。
之后被除数与rdx相加,0x92492493是一个负数补码,若被除数为负,则乘法结果为正,被除数会加一个正数,等于被除数减自身3/7,若被除数为正,则乘法结果为负,被除数会加一个负数,等于被除数减自身3/7。
最后右移2位,得出除以7的结果。
无符号变量除以7
unsigned int a;
scanf("%d",&a);
int b = a / 7;编译器会将除法转换为如下指令:
mov edx,0x24924925 ;乘数写入edx
mov eax,ecx ;被除数写入eax
mul edx ;无符号数乘法
sub eax,edx
shr eax,1
add eax,edx
shr eax,0x2这里除数为7,也会有之前的问题,就是编译器无法计算出误差较小、长度又不超过32位的乘数。
其实第三条乘法指令之后,使用存储乘法结果高32位的edx就是除法结果,只不过这个结果有时候会不太精确,可能会比正确值大1,使用之后的4条指令进行调整将会消除误差。
下面解释后4条指令的作用:
sub eax,edx ;eax为原来的被除数,edx为被除数除以7的结果,eax - edx 等于被除数减自身的1/7,等于取被除数的6/7
shr eax,1 ;被除数的6/7右移一次,等于除以2,等于取被除数的3/7
add eax,edx ;被除数的3/7,加被除数的1/7,等于取被除数的4/7
shr eax,0x2 ;被除数的4/7,再右移2次,等于除以4,等于取被除数的1/7,也就是被除数除以7